What does outstanding stock picking look like?
Most investors would be familiar with the sorts of returns a successful stock-picker might aim to produce. Often, a fund will have an explicit target of beating the market by an amount of, say, 5 per cent per annum over rolling 5-year periods. It is interesting then to think about what it takes to achieve this. In this post, we make some assumptions using recent actual return data for the ASX200 to meet a target.
Of course, there are costs involved, including fees and transaction costs, so to produce this sort of number after expenses, a manager needs to aim for something more before costs. Let’s assume 7 per cent is the number we’re looking for.
It is interesting then to think about what it takes to achieve this, and one way of quantifying what’s needed is using correlation coefficients. For example, let’s say that our manager will analyse all the stocks in the ASX200 and produce for each a return forecast (based on valuation or whatever other philosophy she favours). If we then say she will build a portfolio of the 20 stocks with the highest forecast return, we can work out what correlation coefficient is needed (between her forecasts and the actual results) to achieve the target.
Using these assumptions and some recent actual return data for the ASX200, we can calculate that our manager will need a correlation coefficient in the order of 10 per cent.
The chart below shows what a 10 per cent correlation looks like in a scatter plot. The x-axis is our hypothetical manager’s forecast for each stock; the y-axis is the return that each stock actually achieved during the year. Students of statistics might react to this by saying that 10 per cent is not much correlation at all, and probably not enough to conclude that there’s a relationship between forecast and actual. Non-students of statistics might just look at the chart and think “that’s just a bunch of random dots”. Both are saying the same thing, and both have a fair point.
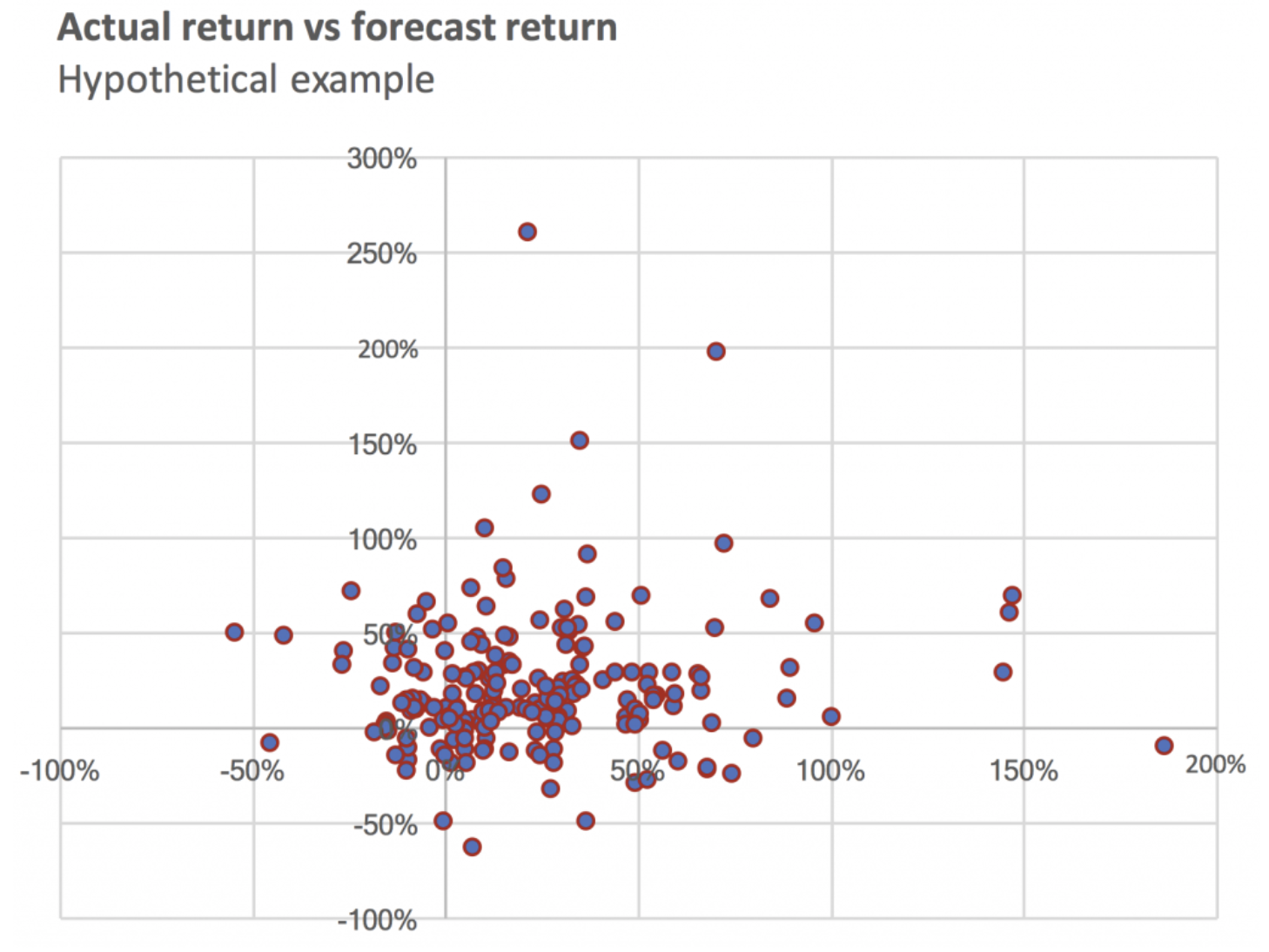
And yet, this seemingly anaemic relationship between forecast and actual is what makes an outstanding stock picker. The force at work here, of course, is market efficiency: There are many, many smart, motivated people trying to pick stocks, and that means that even a very good stock investor has their work cut out for them. In reality, there are very few cases where a stock is an obvious buy or an obvious sell (except in hindsight), and success typically means finding a small edge and applying it consistently over time. Anyone who thinks that they can reliably pick the top-performing stocks probably hasn’t done the math.
A corollary of this is the critical role played by luck. In our sample, above, there are a handful of stocks with exceptional returns, and a handful with very poor returns. Though she may apply her process with absolute consistency, in some years our stock picker will be lucky and have a couple of the former in her portfolio and none of the latter. In other years it will be the opposite. She will be viewed as a genius or an idiot respectively. In reality, she will be neither.
Over much longer timeframes the good and bad luck will tend to balance and the underlying skill will reveal itself, but this takes much longer than most people appreciate. The takeaway, to borrow from Nassim Nicholas Taleb, is try not to be fooled by randomness. Over short periods of time, anything can happen; over longer timeframes (and by that I mean nothing less than 5 years and ideally a lot longer) the truth gradually finds its way to the surface.
If you would like to read more articles by me, please click here.
Never miss an update
Enjoy this wire? Hit the ‘like’ button to let us know.
Stay up to date with my current content by
following me below and you’ll be notified every time I post a wire
Tim Kelley has retired from Montgomery Investment Management, effective 30 September 2021. Tim’s final project has been drafting our investment guidelines to integrate environmental, social and corporate governance (ESG) considerations into our investment process. Tim remains a shareholder of Montgomery Investment Management.

1 topic

Tim Kelley has retired from Montgomery Investment Management, effective 30 September 2021. Tim’s final project has been drafting our investment guidelines to integrate environmental, social and corporate governance (ESG) considerations into our...
Expertise
Tim Kelley has retired from Montgomery Investment Management, effective 30 September 2021. Tim’s final project has been drafting our investment guidelines to integrate environmental, social and corporate governance (ESG) considerations into our...
Expertise
Comments
Comments
Sign In or Join Free to comment
most popular
Investment Theme
If 24 LICs ran the Melbourne Cup, which ones would we back?
Affluence Funds Management